Anaylzer (Analizör)
https://www.elastic.co/blog/found-text-analysis-part-1
Analizörler bilin bakalım ne yapar?
- Analiz :)
Bir girdi çıktı örneğiyle analizör ne yapıyor görelim. Bunun için ES'in standart analizörünü kullanacağız ama bir küçük tanımla ısınalım bu analizöre.
Standard Analyzer : Metni, Unicode Metin Segmentasyonu algoritması tarafından tanımlandığı gibi, kelime sınırlarına göre terimler halinde böler. Çoğu noktalama işaretini kaldırır, kelimeleri küçültür ve durdurma sözcüklerini kaldırmayı destekler.
Şimdi ES'in standart analizörüne Ben Cem TOPKAYA! diyelim ve bakalım giren metni ne hale getiriyor:
POST _analyze
{
"analyzer": "standard",
"text": "Ben Cem TOPKAYA!"
}
Aşağıdaki sonuca bakarsak, şunları yapmış diyebiliriz:
- Analizinde
!işaretini kaldırıyor, - tüm metni küçük harflere çeviriyor,
- bize kelimeleri,
- kelimelerin cümledeki pozisyonlarını,
- kelimelerin ilk ve son karakterlerinin cümlenin başlangıç noktasına göre sıralarını dönüyor.
{
"tokens": [
{
"token": "ben",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "cem",
"start_offset": 4,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "topkaya",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 2
}
]
}
Peki birde Simple Analyzer ile bir metni inceleyelim ama önce Simple Analizör nedir öğrenelim.
Simple Analyzer: Harf olmayan bir karaktere gelince metni parçalayarak token'lar üreten analizördür. Yapısında ne karakter süzgeçleri ne de Token süzgeçleri bulunur. Sadece Lower Case Tokenizer barındıran analizörümüzü aşağıdaki girdiyle deneyelim.
POST _analyze
{
"analyzer": "simple",
"text": "İstanbul'u düşünüyorum gözlerim şeş 5. C#7 çıkmış neyime :=)"
}
Sonuca bakarken harf olmayan karakterlerden kesilerek tokenlar oluştuğunu ve harf olmayanlardan token yaratmadığına dikkat edin [istanbul, u, düşünüyorum, gözlerim, şeş, c, çıkmış, neyime ]
{
"tokens": [
{
"token": "istanbul",
"start_offset": 0,
"end_offset": 8,
"type": "word",
"position": 0
},
{
"token": "u",
"start_offset": 9,
"end_offset": 10,
"type": "word",
"position": 1
},
{
"token": "düşünüyorum",
"start_offset": 11,
"end_offset": 22,
"type": "word",
"position": 2
},
{
"token": "gözlerim",
"start_offset": 23,
"end_offset": 31,
"type": "word",
"position": 3
},
{
"token": "şeş",
"start_offset": 32,
"end_offset": 35,
"type": "word",
"position": 4
},
{
"token": "c",
"start_offset": 39,
"end_offset": 40,
"type": "word",
"position": 5
},
{
"token": "çıkmış",
"start_offset": 43,
"end_offset": 49,
"type": "word",
"position": 6
},
{
"token": "neyime",
"start_offset": 50,
"end_offset": 56,
"type": "word",
"position": 7
}
]
}
Şimdi biraz başa dönerek ANALİZÖR'ün yapısında ne var ona bakalım
Peki bir analizörün yapısı nasıldır?
- 0 veya * CHARACTER FILTER[s]
- 1 adet TOKENIZER
- 0 veya * TOKEN FILTER[s]
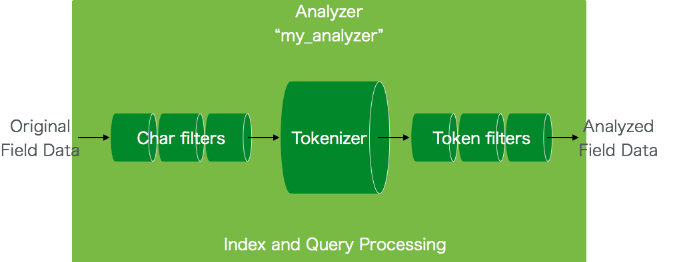
Doğru analizörü seçmek neredeyse bir sanattır. ES, analizörler sayesinde verileri parçalara ayırabilir. Beraberinde çok çeşitli analizörler barındırır. Örneğin:
ES Beraberinde 3 CHARACTER FILTER (karakter süzgeçi), 12 TOKENIZER, ve 31 FILTER(süzgeç)bulundurur. Eğer kendinize göre bir analizör yapmak isterseniz yukarıda adları geçen 3'lüyü biraz daha iyi tanıyalım.
CHARACTER FILTER (Karakter Süzgeci)
Karakter süzgeci sürecin en başındaki kısımdır. Bir veya daha fazla karakter süzgeci kullanarak verinizi değiştirebilirsiniz. Mesela html etiketlerini temizlemek için HTML Strip Character Filter kullanabilirsiniz. Mesela için bul ve değiştir yapmak istediğiniz karakterler Mapping Char Filter ile bulup değiştirebilirsiniz. Mesela düzenli ifadeler ile bul değiştir yapmak isterseniz Pattern Replace Character Filter kullanabilirsiniz.
TOKENIZER
Gelen metni kelimelere ayrıştıran esas parçadır. Mesela whitespace tokenizerını kullandığınızda boşluk karakterlerine bakarak cümleyi kelimelere böler. Bulduğu kelimelerin cümle içindeki sırasını(phrase-ifade- ve proximity queries-yakınlık sorguları- için kullanır) bulur. Ayrıca bu kelimelerin başlangıç ve bitiş karakterlerinin ofset(character offset) değerlerini bulur.
Peki Standard Analyser yapısında ne barındıyordu?
Standart Analizörün yapısında ne var yapısında karakter süzgeçi yok, 1 tokenizer ve 3 token süzgeçi var:

TOKEN FILTER
Buraya kadar geldiğimize göre TOKEN FILTER neymiş ona bakalım. TOKENIZER'dan elimize TOKEN'lar geliyor. Yani ingiliz dili için bakarsak -ed, -ing, -s gibi son eklerden arınmış kelimeleri(TOKEN) süzgeçlerden geçirir. Mesela küçük harfle yazmak için Lowercase Token Filter kullanır. Mesela Türkçemizdeki İ-i ya da I-ı gibi dönüşümlere uygun olacak şekilde küçük harfli formunu verir.
CUSTOM ANALYZER (Kendi analizörümüz olsun artık)
Biraz daha güzel bir örnek yapalım. Stop Words denilen ara kelimelerimizi TOKEN akışımızdan çıkartmak için Stop Token Filter kullanalım. Önce kendi analizörümüzü bir indeks içinde tanımlayalım ki, girdiğimiz metinlerimizi bu analizöre göre indekslesin.
my_index Adında bir indeks tanımlayalım. settings -> analysis -> analyzer içinde my_turkce_analyzer isimli analizör tanımlayalım.
type ile bu analizörümüzün standart olduğunu ve biraz özel konfigurasyona sahip olacağını belirtiyoruz.
max_token_length ile bir tokenın en çok kaç karakter olacağını belirtelim.
stopwords ile oluşan tokenlar içinde eğer stopwords tokenları varsa onları sonuçtan çıkartacağımızı söylüyoruz.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_turkce_analyzer": {
"type": "standard",
"max_token_length": 35,
"stopwords": [
"benim",
"beri",
"cem"
]
}
}
}
}
}
Bir örnekle nasıl çalıştığını görelim:
POST my_index/_analyze
{
"analyzer": "my_turkce_analyzer",
"text": "benim adım Cem. C, F#, C++ hepiciğini Öteden beri yazılımı sevmişimdir."
}
Sonuç elbette karakter ve en önemlisi STOPWORDS içinde olmayan tokenlardan oluşuyor(beri, benim, cem yok ;)[adım, c, f, c, hepiciğini, öteden, yazılımı, sevmişimdir]
{
"tokens": [
{
"token": "adım",
"start_offset": 6,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "c",
"start_offset": 16,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "f",
"start_offset": 19,
"end_offset": 20,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "c",
"start_offset": 23,
"end_offset": 24,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "hepiciğini",
"start_offset": 27,
"end_offset": 37,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "öteden",
"start_offset": 38,
"end_offset": 44,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "yazılımı",
"start_offset": 50,
"end_offset": 58,
"type": "<ALPHANUM>",
"position": 9
},
{
"token": "sevmişimdir",
"start_offset": 59,
"end_offset": 70,
"type": "<ALPHANUM>",
"position": 10
}
]
}
Peki bu stopwords için tüm kelimeleri tek tek ekleyecek miyiz?
- LUCENE içinde zaten tanımlı oldukları için
"stopwords" : "_turkish_"dememiz yetecek. Bakın neler bu Türkçe stopwords kelimeler.
Haydi şu my_index siline (DELETE my_index)ve tekrar oluşturula:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_turkce_analyzer": {
"type": "standard",
"max_token_length": 35,
"stopwords": "_turkish_"
}
}
}
}
}
Demekki stopwords _english_ gibi başka diller de olabilir. Buraya kadar güzel geldik. Az önce Simple Analyzer görmüştük ve kendi analizörümüzü tasarlarken için eklediğimiz STOPWORDS ile aslında yeni bir analizör daha öğrendik: Stop Analyzer . Simple Analyzer üstüne bir STOPWORDS özelliği alınca Stop Analyzer oldu. Varsayılan olarak ingilizce olan bu analizörü eğer kendimize göre değiştirerek kullanmak isteresek aşağıdaki şekilde bir indeks oluşturmamız yetecek.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_turkce_stop_analizorum": {
"type": "stop",
"max_token_length": 35,
"stopwords": "_turkish_"
}
}
}
}
}
Testimizi yapacağız ve sonuç kümesinde benim, beri tokenlarını göremeyeceğiz çünkü Türkçe stopwords bu kelimeleri içerdiği için onlara STOP diyor ;)
{
"tokens": [
{
"token": "adım",
"start_offset": 6,
"end_offset": 10,
"type": "word",
"position": 1
},
{
"token": "cem",
"start_offset": 11,
"end_offset": 14,
"type": "word",
"position": 2
},
{
"token": "c",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 3
},
{
"token": "f",
"start_offset": 19,
"end_offset": 20,
"type": "word",
"position": 4
},
{
"token": "c",
"start_offset": 23,
"end_offset": 24,
"type": "word",
"position": 5
},
{
"token": "hepiciğini",
"start_offset": 27,
"end_offset": 37,
"type": "word",
"position": 6
},
{
"token": "öteden",
"start_offset": 38,
"end_offset": 44,
"type": "word",
"position": 7
},
{
"token": "yazılımı",
"start_offset": 50,
"end_offset": 58,
"type": "word",
"position": 9
},
{
"token": "sevmişimdir",
"start_offset": 59,
"end_offset": 70,
"type": "word",
"position": 10
}
]
}
Kavrayışımız daha artıyor besbelli. O halde durmayalım ve okumaya denemeye gaz verelim. Kazım Koyuncu'dan Narino ne güzel gider şimdi değil mi?